Yeah if your willing to carry a brick or at least a power bank (brick) if you don’t want it to constantly overheat or deal with 2-3 hours of battery life. There’s only so much copper can take and there are limits to minaturization.
It’s not like that though. Newer phones are going to have dedicated hardware for processing neural platforms, LLMs, and other generative tools. The dedicated hardware will make these processes just barely sip the battery life.
if that existed, all those AI server farms wouldn’t be so necessary, would they?
dedicated hardware for that already exists, it definitely isn’t gonna be able to fit a sizeable model on a phone any time soon.
models themselves require multiple tens of gigabytes of storage space. you won’t be able to fit more than a handful on even a 512gb internal storage. the phones can’t hit the ram required for these models at all. and the dedicated hardware still requires a lot more power than a tiny phone battery.


{kind=link}
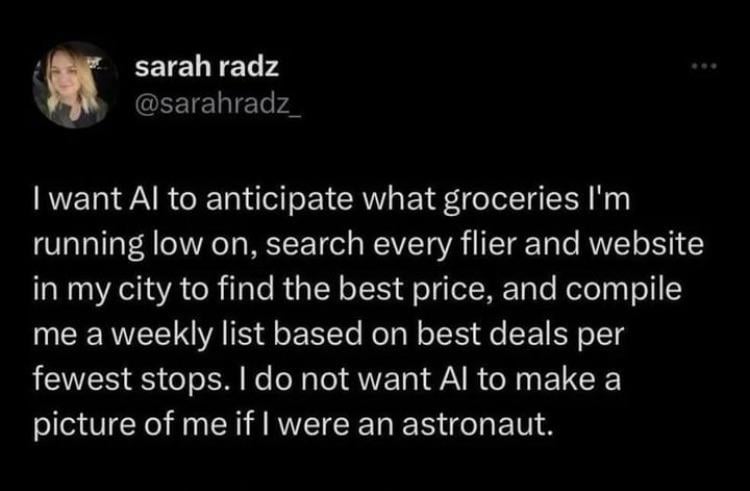
This technology will be running on your phone within the next few years.
Because like every other app on smartphones it’ll require an external server to do all of the processing
I mean, that’s already where we are. The future is going to be localized.
Yeah if your willing to carry a brick or at least a power bank (brick) if you don’t want it to constantly overheat or deal with 2-3 hours of battery life. There’s only so much copper can take and there are limits to minaturization.
It’s not like that though. Newer phones are going to have dedicated hardware for processing neural platforms, LLMs, and other generative tools. The dedicated hardware will make these processes just barely sip the battery life.
wrong.
if that existed, all those AI server farms wouldn’t be so necessary, would they?
dedicated hardware for that already exists, it definitely isn’t gonna be able to fit a sizeable model on a phone any time soon. models themselves require multiple tens of gigabytes of storage space. you won’t be able to fit more than a handful on even a 512gb internal storage. the phones can’t hit the ram required for these models at all. and the dedicated hardware still requires a lot more power than a tiny phone battery.
Those server farms are because the needs of corporations might just be different from the needs of regular users.
I’m running a 8 GB LLM model locally on my PC that performs better than 16 GB models from just a few months ago.
It’s almost as if technology can get better and more efficient over time.