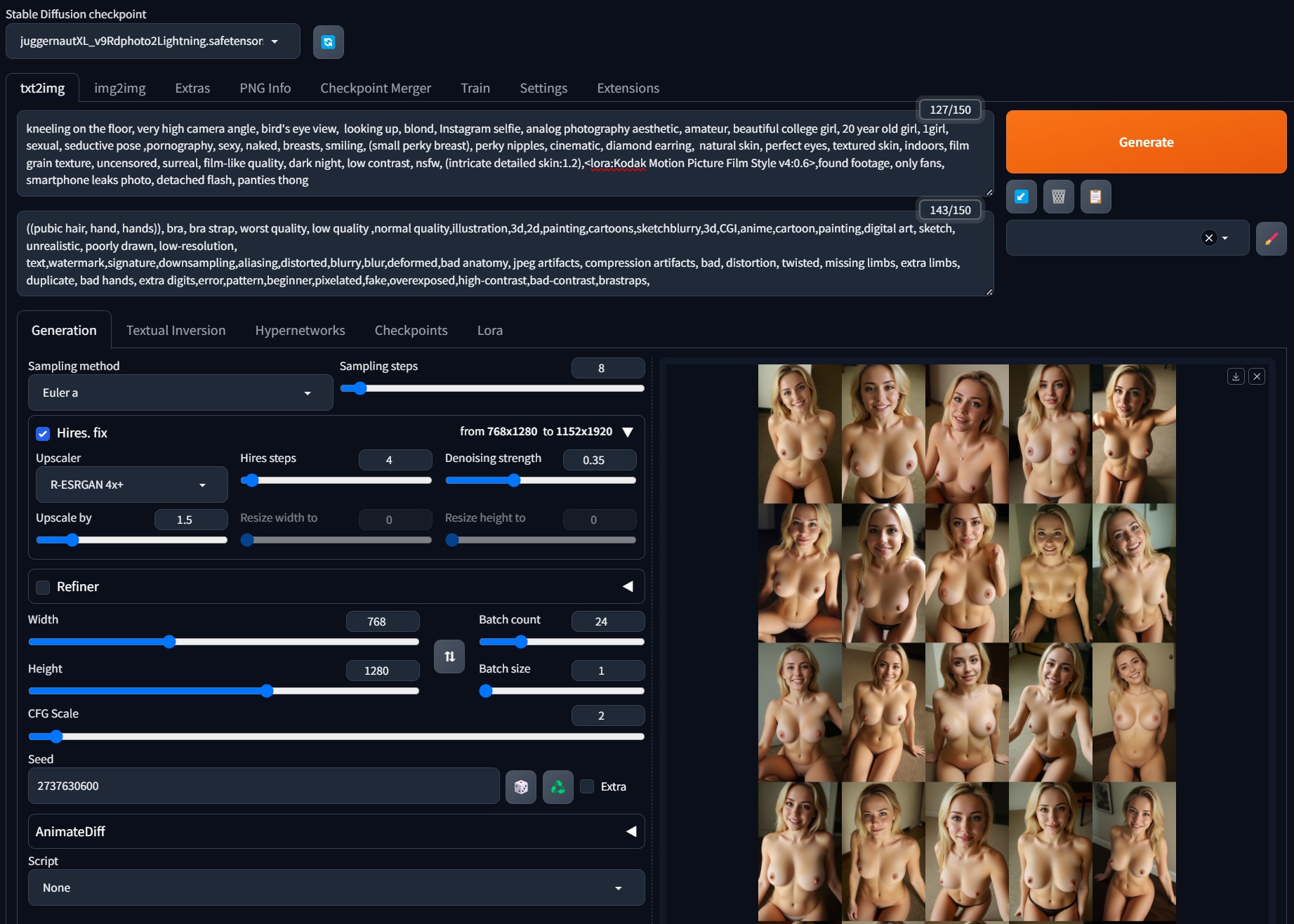
I had a request for more info on my workflow. The last photo of the album is my setup. These took about 26 seconds each on an RTX 4070 and overflowed the 12GB of VRAM by about an additional 5GB during the ‘Hires fix’ phase (no big deal just slows thing down). Below the album you’ll find a Python script I use to build the album after I upload the images. About half of them were ‘good enough’ to include in the album.
Click on an image to see prompt details. Check out my post history for more.








Input file will look like this:
https://image.delivery/page/adezoha
https://image.delivery/page/dkckyle
...
Output will look like this:
[][1]
[][2]
[1]: https://image.delivery/page/adezoha
[2]: https://image.delivery/page/dkckyle
Python script:
def convert_urls(input_file, output_file):
with open(input_file, 'r') as f:
urls = f.read().splitlines()
with open(output_file, 'w') as f:
f.write('Click on an image to see prompt details.\n')
f.write('Check out my post history for more.\n\n')
for i, url in enumerate(urls, start=1):
id = url.split('/')[-1]
if (url):
f.write(f'[][{i}]\n')
f.write('\n')
for i, url in enumerate(urls, start=1):
if(url):
f.write(f'[{i}]: {url}\n')
# Usage
convert_urls('input.txt', 'output.txt')
Yeah two-step was my workaround. Running Linux here, so probably a different beast altogether.