

{kind=link}
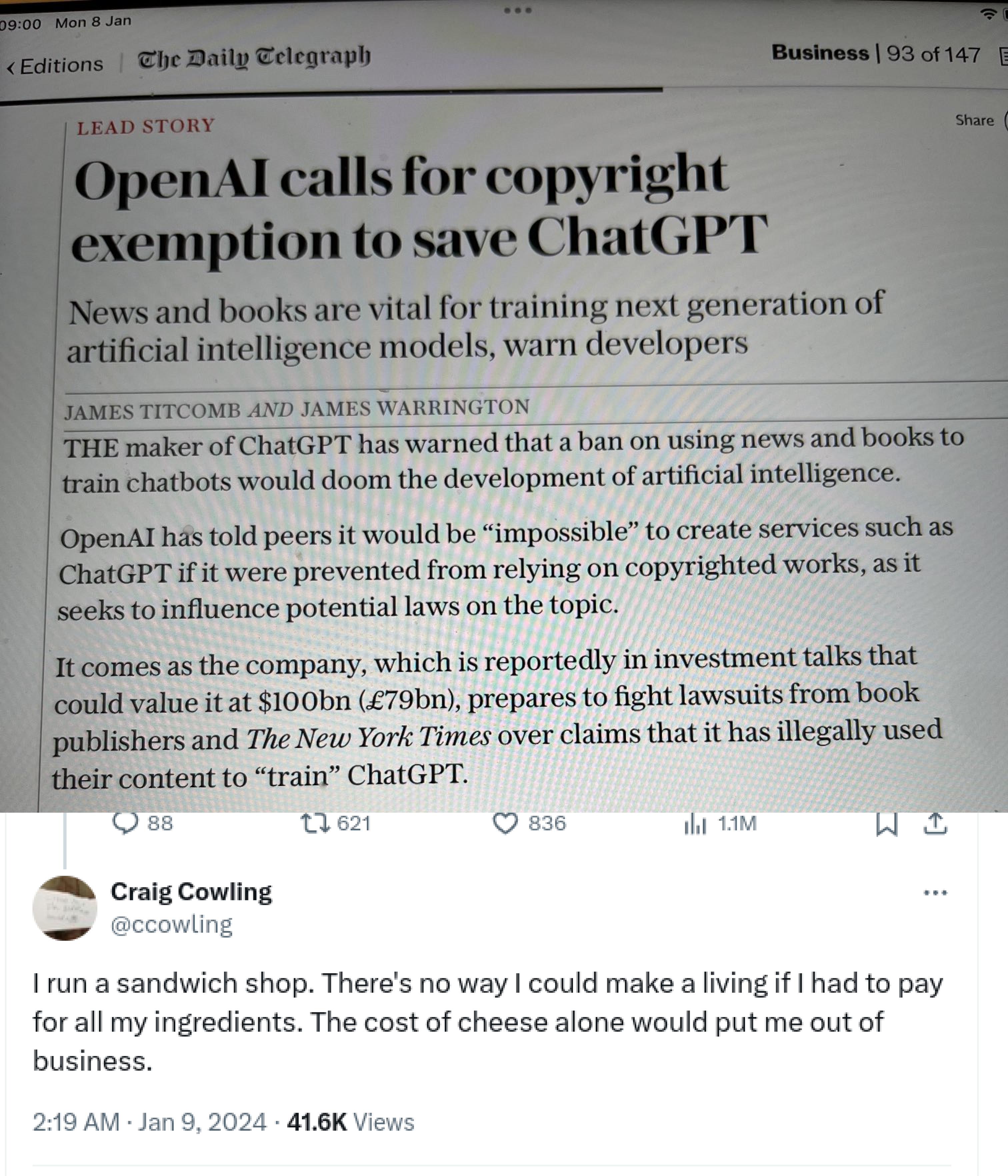
Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
Personally for me its about the double standard. When we perform small scale “theft” to experience things we’d be willing to pay for if we could afford it and the money funded the artists, they throw the book at us. When they build a giant machine that takes all of our work and turns it into an automated record scratcher that they will profit off of and replace our creative jobs with, that’s just good business. I don’t think it’s okay that they get to do things like implement DRM because IP theft is so terrible, but then when they do it systemically and against the specific licensing of the content that has been posted to the internet, that’s protected in the eyes of the law
Kill a person, that’s a tragedy. Kill a hundred thousand people, they make you king.
Steal $10, you go to jail. Steal $10 billion, they make you Senator.
If you do crime big enough, it becomes good.
No, no it doesn’t.
It might become legal, or tolerated, or the laws might become unenforceable.
But that doesn’t make it good, on the contrary, it makes it even worse.
That’s their point.
No shit
I mean openais not getting off Scott free, they’ve been getting sued a lot recently for this exact copy right argument. New York times is suing them for potential billions.
Do they though, since the Metallica lawsuits in the aughts there hasnt been much prosecution at the consumer level for piracy, and what little there is is mostly cease and desists.
What about companies who scrape public sites for training data but then publish their trained models open source for anyone to use?
That feels a lot more reasonable and fair to me personally.
If they still profit from it, no.
Open models made by nonprofit organisations, listing their sources, not including anything from anyone who requests it not to be included (with robots.txt, for instance), and burdened with a GPL-like viral license that prevents the models and their results from being used for profit… that’d probably be fine.
And also be useless for most practical applications.
We’re talking about LLMs. They’re useless for most practical applications by definition.
And when they’re not entirely useless (basically, autocomplete) they’re orders of magnitude less cost-effective than older almost equivalent alternatives, so they’re effectively useless at that, too.
They’re fancy extremely costly toys without any practical use, that thanks to the short-sighted greed of the scammers selling them will soon become even more useless due to model collapse.