

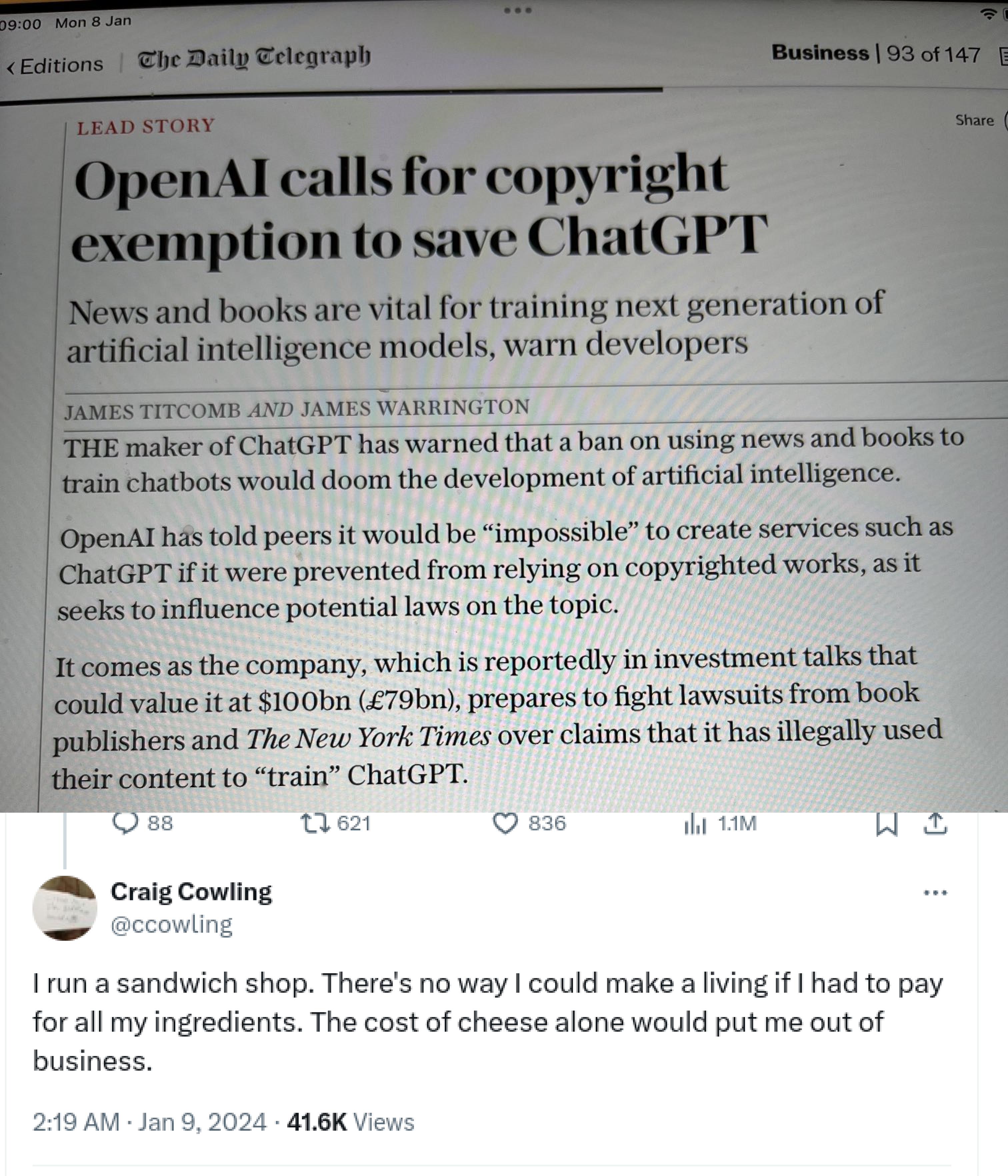
{kind=link}
Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
Just a point of clarification: Copyright is about the right of distribution. So yes, a company can just “download the Internet”, store it, and do whatever TF they want with it as long as they don’t distribute it.
That the key: Distribution. That’s why no one gets sued for downloading. They only ever get sued for uploading. Furthermore, the damages (if found guilty) are based on the number of copies that get distributed. It’s because copyright law hasn’t been updated in decades and 99% of it predates computers (especially all the important case law).
What these lawsuits against OpenAI are claiming is that OpenAI is making a derivative work of the authors/owners works. Which is kinda what’s going on but also not really. Let’s say that someone asks ChatGPT to write a few paragraphs of something in the style of Stephen King… His “style” isn’t even cooyrightable so as long as it didn’t copy his works word-for-word is it even a derivative? No one knows. It’s never been litigated before.
My guess: No. It’s not going to count as a derivative work. Because it’s no different than a human reading all his books and performing the same, perfectly legal function.
It’s more about copying, really.
People do get sued in some countries. EG Germany. I think they stopped in the US because of the bad publicity.
That theory is just crazy. I think it’s already been thrown out of all these suits.