

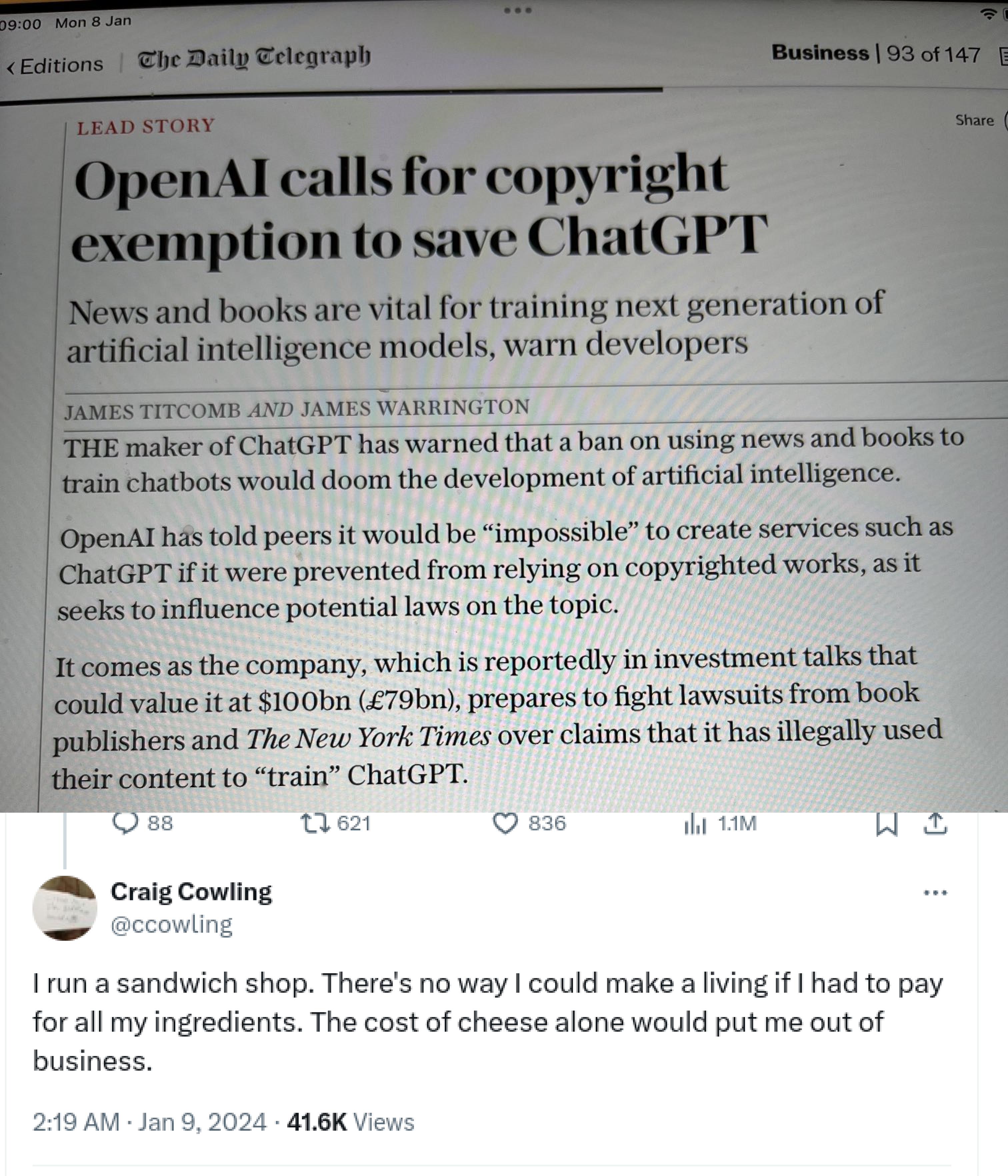
{kind=link}
Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
Y’all should really stop expecting people to buy into the analogy between human learning and machine learning i.e. “humans do it, so it’s okay if a computer does it too”. First of all there are vast differences between how humans learn and how machines “learn”, and second, it doesn’t matter anyway because there is lots of legal/moral precedent for not assigning the same rights to machines that are normally assigned to humans (for example, no intellectual property right has been granted to any synthetic media yet that I’m aware of).
That said, I agree that “the model contains a copy of the training data” is not a very good critique–a much stronger one would be to simply note all of the works with a Creative Commons “No Derivatives” license in the training data, since it is hard to argue that the model checkpoint isn’t derived from the training data.
Not really. First of all, creative commons strictly loosens the copyright restrictions on a work. The strongest license is actually no explicit license i.e. “All Rights Reserved.” No derivatives is already included under full, default, copyright.
Second, derivative has a pretty strict legal definition. It’s not enough to say that the derived work was created using a protected work, or even that the derived work couldn’t exist without the protected work. Some examples: create a word cloud of your favorite book, analyze the tone of news article to help you trade stocks, produce an image containing the most prominent color in every frame of a movie, or create a search index of the words found on all websites on the internet. All of that is absolutely allowed under even the strictest of copyright protections.
Statistical analysis of copyrighted materials, as in training AI, easily clears that same bar.