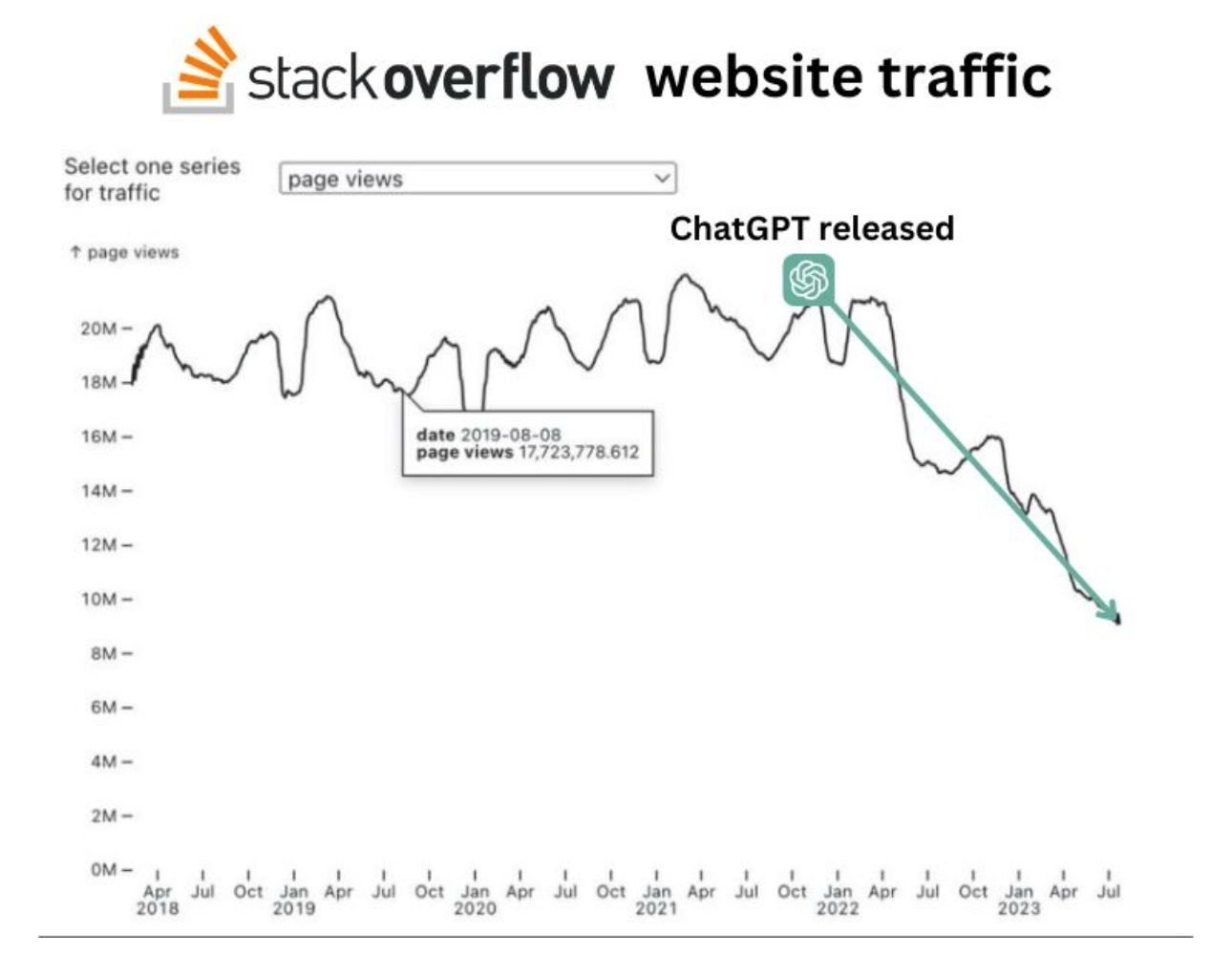
Wonder where chatgpt will get its training data in the future, as it’s known not to extrapolate well. Where will it learn new frameworks, languages, … from?
I doubt it ever scraped SO, otherwise all the answers would be smth along the lines: “I cannot answer this question due to low quality effort!” closes browser window
Honestly it’s petty good about doing that. Already had similar tooling options but it does a generally good job of making docs for non devs assuming good naming are used in the methods
That works when the docs are good and clear. Otherwise, we’ll have to revert to communicating with each other for brief periods while the chat-bots train themselves on the new data.


{kind=link}
Wonder where chatgpt will get its training data in the future, as it’s known not to extrapolate well. Where will it learn new frameworks, languages, … from?
Its going to starve itself.
Let it die
I doubt it ever scraped SO, otherwise all the answers would be smth along the lines: “I cannot answer this question due to low quality effort!” closes browser window
The documentation?
The docs. It’s what it does now a lot of the time I’ve noticed.
Auto generated docs since devs don’t document?
Chatgpt, look at this repo and write docs
Honestly it’s petty good about doing that. Already had similar tooling options but it does a generally good job of making docs for non devs assuming good naming are used in the methods
Yeah the smaller the project the less effective this is.
But even learning from the source code is pretty effective.
That works when the docs are good and clear. Otherwise, we’ll have to revert to communicating with each other for brief periods while the chat-bots train themselves on the new data.
A lot of models are being trained on “synthetic” data now, right?
Even when a parrot learns to parrot a parrot, the first parrot still has to be taught.