

A couple of years ago I found a black and white photo from the late 1800s and wanted to figure out what station it was from. Google was useless and only showed unrelated stations, but surprisingly, Bing found a page with the exact photo on it. It was on one of those shitty scraper pages that just lists thousands and thousands of random photos, but nonetheless I figured out what station it was
Jesus Christ I guess I’m not misremembering.
Bing’s reverse image search is essentially dead in 2024 unless you’re uploading the Mona Lisa. It’s really, really terrible and even worse than Google.
My favorites right now are Tineye, Yandex, and Google, in that order.
Strange, for me Tineye has not a single time been able to identify ANY of the images I ever tried. Yandex has worked best for me
Same, tineye only ever worked for me if I uploaded a picture that was by Reuters or something and therefore on lots of reputable sites. In any other cases it found nothing.
My last experience with bings reverse image search was in 2022 or so, so no vouches for its quality these days. I’ve had mixed results with tineye, but there was another one which I don’t even remember the name of that generated reverse search links for all the search engines, I think it even listed that Chinese one and a few others I’ve never heard of rather than being its own thing. I had decent luck with that, I found Bing still worked the best but I haven’t tried it since
Google lens definitely wins for object search though. Not the point of the post, I know, but it’s kind of funny how their reverse image search is dogshit but their object recognition is flawless
Please please come back when you remember the name of what you’re talking about.
I would search for it myself, but you know, it’s not 2003 to 2022 anymore.
Found it. It’s https://www.reverseimagesearch.com/. It doesn’t list as many as I thought, just google, Bing, Yandex, and Baidu
Thank you!!
This sounds like what reverseimagesearch dot org does, but that only has 4 engines linked.
Just that name Tineye. Now I need to find images I have a reason to search.
Does it have connotations? I don’t know them.
Tineye? Yea it’s used in Branden Sanderson’s Mistbourne books. People have the ability to ingest different metals for different abilities.
People who ingest tin, gain heightened senses. Vision, hearing, touch, etc. They are known as “tineyes”.
Cooooool. Thank you.
Neither ever worked for lineart. Photos? Used to be reliable, occasionally bordered psychic, now just dumb. Drawings? Yep, that’s a drawing. Did you need anything else?
It does seem like the ideology of those inside google went from “tech” , to “I know better than you do”. Not sure it’s fixable really…
That’s the problem with most tech these days. They assume they know the best way to do something or know better than you. Its infuriating
Spotify is a prime example of this. There are so many “features” I hate and that no one has asked for, yet shuffle doesn’t even work.
Everytime I start spotify in ny office after listening on my commute, it tries to start playing on my phone since that was playing in my car.
Or when I was still there, Reddit search. Absolutely useless and so fucking smarmy with that stupid doge.
What do you mean by “shuffle doesn’t even work”? Please qualify that statement.
they may be referring to how spotify’s shuffle isn’t a true “shuffle” in that it is biased to things you have listened to more, recently, etc
That’s been the case for well over a decade going back to some of the earliest iPods. It’s nothing new.
https://pullpush.io is the good reddit search
They know how to manipulate you to do/buy stuff you weren’t looking for. That’s what makes a profit.
It has always been this way (also in tech) because those things are the products of companies (main goal: profit, usually under a sneaky slogan), but it is becoming increasingly invasive. Don’t be evil: think different.
Removed by mod
Yeah, tech people nowadays have this attitude with most people, they only show some restraint when they think it’s for other people like them.
It’s about minimizing the annoyance for the majority of users who will misspell some popular thing.
Also, I believe that showing actually interesting content is bad for the businesses because it might make the user stop to think and pursue something meaningful instead of continuing to use the product.
Very interesting article. Prabhakar Raghavan’s basically Ted Faro.
That was great, thank you for linking! I expected to just skim it and ended up reading the whole article and the follow-up
Damn, yeah, Ragavan is definitely killing Modern search
Unrealistic. I usually have to scroll way down in the results to find a link to wikipedia nowadays.
So true. If I want to know how old a celebrity is, first result is something about their latest work that doesn’t mention age, and then the next 3-4 are usually some ranking articles, “top 10 ceberities you didn’t know were 50,” and then Wikipedia comes in with the answer.
Best erotica books 2024 listings occupy the first 5 positions.
Yandex, my friends
I don’t even care if the results are good. I’m not about to use any part of RUnet.
Why noy? RuTracker is better than any other tracker, open or private.
I’m going to make the assumption that a lot of people on Lemmy are FOSS enthusiasts and are therefore adverse to anything closed source, especially a Russian web service…
What? We’re talking about websites, not software here
Guess what websites are made of
Oh I know this one!
It’s pipes, right‽
Tubes
I thought it was dump trucks
Apparently the brigade has found you, but i want you to know that i agree (mostly). Obviously it kind of sucks tohavve Russian as the default language on everything you get from there, and there’s some super-obscure music I’ve failed to find on there, but it’s basically my first stop these days, whether it’s Abbot Elementary or CompTIA training videos.
Honest question: why not? Facebook/Google/Microsoft are up to some disgusting shit, are their Russian counterparts significantly different?
Privacy, for one thing. I don’t use Google, Bing, Windows, or any Meta software*, and Yandex aren’t much different.
Security, though, is another thing. I live in a NATO country, and I would imagine the Russian government are monitoring Yandex (and other RUnet services). Frankly, I think contributing any data to such a government would be against my interests.
There’s also a lot of censorship on RUnet. Yeah, Google has that too, but Mojeek and Brave Search do not.
TL;DR: Google is data-hungry and supplies data to the NSA; Yandex is data-hungry and supplies data to the Kremlin; Mojeek and Brave Search are good; DDG and Startpage are the best for the average user.
Don’t be a pussy
Yandex reverse image search often works considerably better than Google’s.
And their translator too. I use it all the time for Latin. Google Translate was made mostly for Romance and Germanic languages, so it sucks at assigning the right case to Latin, and the word order is often a mess. Yandex was however made with Russian in mind, that is
syntacticallyEDIT: grammatically* closer to Latin in those two aspects.*case division is morphology in this case.
Oh you too are versed in the language of Romance?
Yes! Video related, that’s me!
Serious now. It’s just that I don’t recall which Latin descendants Google supports, and I’m not going to check it.
I had 6 years of Latin in school and remember less than 1% of it. Talk about a waste of time. Bada bing bada boom shoulda learned Italian-English rather.
Sure. I’m not saying that Latin is useful for most people. It isn’t; I don’t expect most people to fuck around with Plautus, Cicero, Catullus etc. I’m saying that Yandex Translate is useful for me because of decent support for Latin, while Google offers better support for a handful of Latin descendants aka Romance languages (like Italian).
And it’s mostly due to a coincidence - because the platform was made by Russian speakers and Russian happens to still keep a similar case system as Latin does.
(…anche parlo italiano, ma davvero per italiano non uso nessuno - se non so qualcosa uso dizionari. Dà meno lavoro.)
Fuhgeddaboudit
Sounds a little suss. All the propaganda I see about Latin mentions its free word order.
Word order in Latin is only syntactically free. As in, if you change the word order, you aren’t changing who did what. However, you’re still changing the topic (whatever we were talking about) and comment (the new info that I’m adding in).
I’ll give you an example:
- Puer puellam amat - boy loves girl; but more like “the boy loves a girl”.
- Puellam puer amat - boy loves girl; but more like “a boy loves the girl”.
- Amat puer puellam - boy loves girl; but more like “speaking on love, the boy loves a girl” (hard to convey in English).
Note how I used articles to convey roughly the same meaning in English. That’s because what Latin is doing with the word order is not too unlike what English does with articles. Sure, you can use “the boy”, “a boy”, or simply “boy”, it won’t change the basic meaning, but it’s still not “random”.
And guess which language happens to use a similar system? Russian. The only major difference is that by default (i.e. you aren’t focusing on any element), Latin would put the verb at the end and Russian in the middle; but it’s the same variability.
I can’t use Yandex as it just makes me complete endless capchas
Maybe you are a robot
Does that mean it should have its time wasted? Anti-robot bigotry is at an all time high and I, for one, think it’s time for change.
Found another one.
It’s a little less awful when you’re not on a VPN, but even if it had twice as many captchas, it’s reverse image search is so much better than Google’s and Bing’s how that it’d still be worth it.
Also consider Tineye.
What’s yandex?
Russian search engine
Tineye
I rarely have to use it, but for me it works every time.
Perversity and males in Japan. Name a better team.
I would bet money they’re not from or in Japan. On this particular 4chan board you can choose any flag you want when posting.
They could be Weeaboo expats in Japan, but I agree definitely not born and raised in Japan, you can tell by how they write English.
Guns and schools in America. Name a better team.
The 95-96 Chicago Bulls, you despicable white knight weeaboo?
Weeaboo is when I make fun of you for generalizing an entire population
Which I didn’t do, you half witted ding dong? Can you read?
There is a firefox addon for it called search by image not sure how good it is tho as i have never used it .
:(
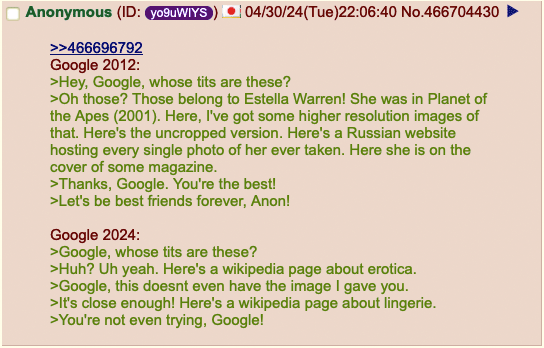
Man, Anon just wanted to know, “Whose tits are these?”. Sad times.














{kind=link}